news Release
June 18, 2025
Wilmington, Mass.
Custom Keyword Spotting at the Edge: Lightweight, Accurate, and Easy to Use
A new voice recognition approach offers accuracy, adaptability, and efficiency for low-power hardware.
Voice control is essential for modern interfaces, from smart homes to in-car systems. Alexa, Siri, and ‘Hey Google’ are now part of our day-to-day lives. However, building keyword spotting (KWS) models that are both efficient and adaptable remains a significant challenge—especially on edge devices where memory and compute resources are limited. Overcoming these challenges requires a holistic approach matching hardware, software and AI.
A team from Analog Devices, Inc. (ADI), led by Alican Gok, Oguzhan Buyuksolak and Erman Okman, developed a new customizable KWS approach as part of Alican's PhD thesis with Prof. Murat Saraclar of Boğaziçi University. This approach significantly reduces resource demands and allows users to easily add their own keywords without needing retraining or machine learning expertise. It achieves this by using neural network models that distill the expertise of task-agnostic self-supervised learning (SSL) models.
The Challenge with Traditional KWS Systems
Conventional KWS systems face two key limitations:
- High resource demands: Many models require tens to hundreds of megabytes of memory, making them impractical for edge deployment.
- Data-heavy customization: Adapting to new keywords typically involves collecting thousands of training samples per keyword. Better models also incorporate datasets with diverse accents, dictions, and voices.
To address these issues, the team introduced a two-step architecture combining the strength of large, open-source models with the efficiency needed for real-world edge applications.
Figure 1 (a) Proposed approach for edge Few Shot-Keyword Spotting (FS-KWS) model training and (b) block diagram of a FS-KWS application at the edge.
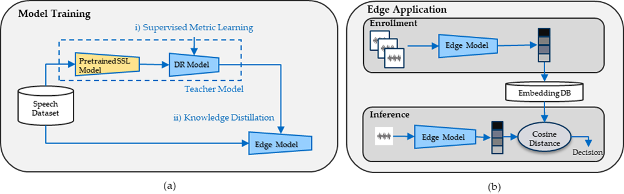
From Heavyweight Learning to Lightweight Inference
The team’s method starts by training a powerful "teacher" model based on Meta's wav2vec2 architecture to extract rich audio embeddings from raw speech. This model, with over 300 million parameters, is not designed for the edge. Instead, the team used it to train a compact "student" model that can operate efficiently on-device at the edge.
The model then reduces wav2vec2 embeddings from 49x1024 dimensions to more manageable sizes (1x32, 1x64, or 1x128) for a one-second audio sample. The reduction process preserves the distinctions necessary for recognizing different keywords. This is achieved using a self-attention-based reduction model trained with subcenter arcface loss to improve keyword separation.
Efficient Models, Real-Time Performance
For the edge model, the team explored several architectures, including convolutional neural networks (CNNs) with sizes ranging from 10,000 to 1 million parameters. To facilitate an apples-to-apples comparison with leading few-shot KWS systems, the team trained a compact ResNet model—identical to those used by the top systems—on the Multilingual Spoken Words Corpus (MSWC) and benchmarked against the Google Speech Commands (GSC) dataset.
By distilling knowledge from the teacher model, the student model maps audio input to keyword-relevant embeddings, which are then matched against a user-defined database using cosine similarity.
Simple Customization, No Retraining Needed
Users can customize the system by providing a few new keyword examples. The inference process adds these keywords to its embedding database. A threshold parameter allows tuning between detection sensitivity and false alarm rates, offering flexibility across use cases.
Proven Results, Ready for Deployment
Our latest model outperforms leading few-shot KWS systems across all tested operating points, as shown by receiver operating characteristic (ROC) curves and benchmark comparisons.
We're optimizing model architecture for deployment on ADI's current MAX78000 and upcoming hardware, bringing powerful, customizable voice recognition to the intelligent edge. Ready to learn more?
Please read the full paper below.
FewShotKWS_IEEESignalProcessingLetters [IEEE paper submission]